 En los últimos años, una generación emergente de sistemas automáticos de detección del discurso de odio en internet ha comenzado a ofrecer nuevas estrategias para combatir este material ofensivo.
En los últimos años, una generación emergente de sistemas automáticos de detección del discurso de odio en internet ha comenzado a ofrecer nuevas estrategias para combatir este material ofensivo.
Anticipando la eficacia futura de tales sistemas, expertos de la Universidad de Cambridge han publicado un artículo en la revista “Ethics and Information Technology” en el que proponen aprovechar las técnicas de seguridad cibernética para que los usuarios de redes sociales puedan controlar los mensajes a los que se exponen, sin recurrir a la censura.
Si una publicación determinada se clasifica automáticamente como dañina de manera confiable, entonces se puede poner en cuarentena temporalmente, y los destinatarios directos pueden recibir una alerta, que los protege del contenido dañino en primera instancia.
Relacionado
-

¿Qué es el discurso de odio?
El discurso de odio es un lenguaje que ataca o menosprecia, que incita a la violencia o al odio contra los grupos, en función de características específicas como la apariencia física, la religión, la ascendencia, el origen nacional o étnico, la orientación sexual, la identidad de género u otro, y explicitarse de distintas formas, incluso sutiles cuando se usa el humor.
Durante la última década, el rápido crecimiento de las redes sociales ha creado nuevas formas de comunicación rápida y eficiente en las que el discurso de odio se puede expresar casi instantáneamente en línea y, a menudo, de forma anónima.
Reconociendo los problemas que esto crea, los proveedores de redes sociales y las plataformas de intercambio de videos como YouTube, Facebook y Twitter han desarrollado políticas internas para la regulación del discurso del odio, y también firmaron un acuerdo de Código de Conducta con la Comisión Europea.
En la actualidad, tales decisiones se toman en el ámbito corporativo, en lugar de a nivel estatal, lo que significa que las empresas en cuestión se autorregulan. Sin embargo, los métodos aplicados para atajar el discurso del odio son inherentemente reactivos, y esto es un problema porque significa que el daño ya ha sido infligido.
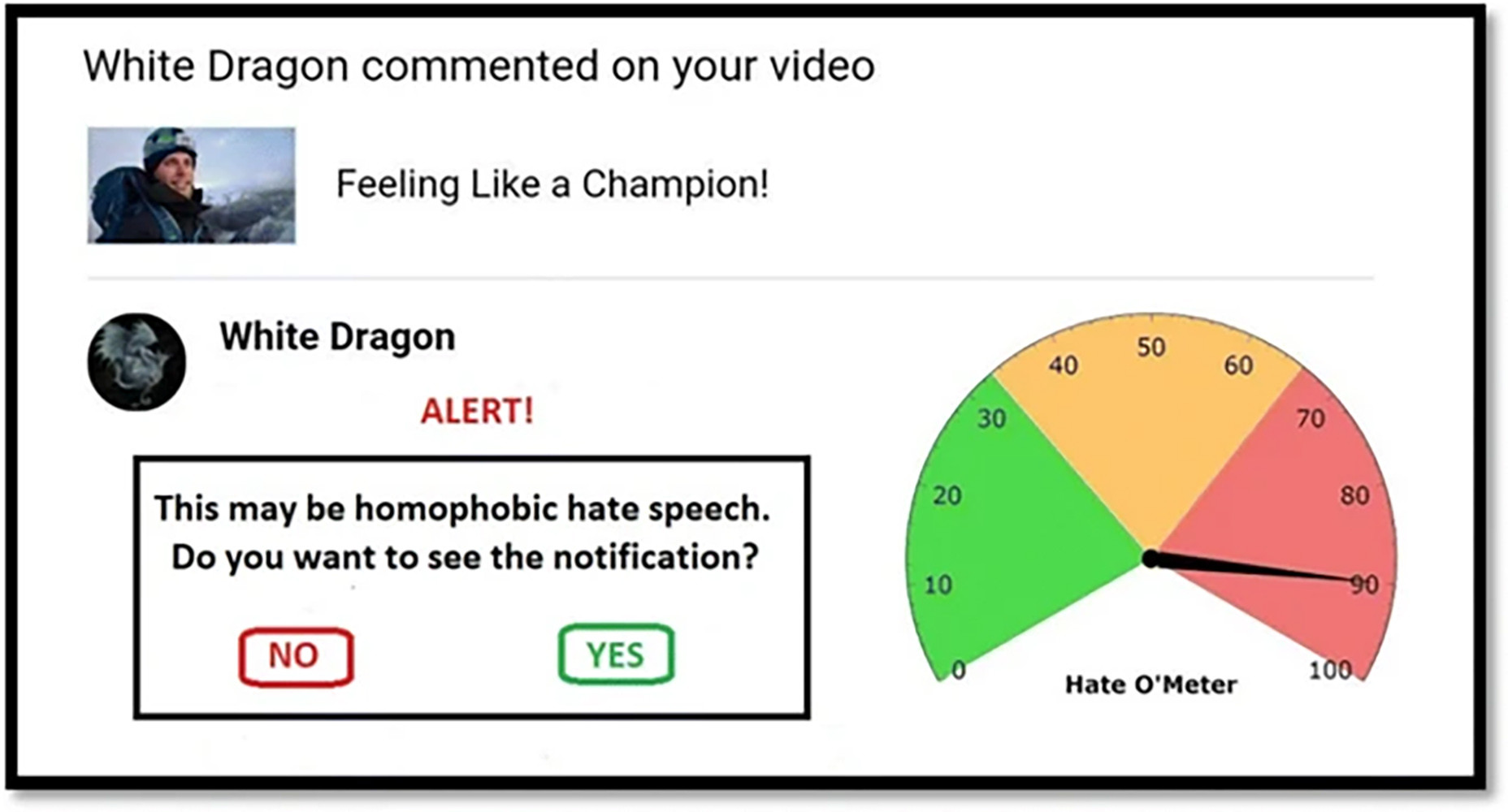
La naturaleza lenta y laboriosa de este sistema reactivo ha llevado a la convicción de que se requieren sistemas automatizados para detectar dicho material. Y la necesidad de definir el discurso de odio con mayor precisión para estos fines (por ejemplo, para que los datos de entrenamiento de inteligencias artificiales se puedan tomarr con precisión) ha enfatizado aún más las ambigüedades inherentes al mismo concepto. Los tipos de mensajes así clasificados varían internacionalmente, en gran parte porque las leyes de adoptan una variedad de formas diferentes dependiendo de las definiciones legales adoptadas en diferentes países.
Dada la complejidad de la tarea de moderar mensajes ofensivos, es importante considerar una forma alternativa de censura (potencialmente temporal), a saber, la cuarentena. Este enfoque, propuesto por los investigadores Stefanie Ullmann y Marcus Tomalin, ha sido habitual en las aplicaciones de seguridad cibernética desde fines de la década de 1980, especialmente como una forma de protección contra el malware.
Insultos que son malware
Por analogía, el discurso de odio puede verse como otra forma de daño intencional en línea y, por lo tanto, también puede manejarse mediante la cuarentena. La analogía es menos imprecisa de lo que puede parecer inicialmente, ya que el discurso de odio en línea a veces es generado por software (por ejemplo, por bots de Twitter). Por lo tanto, cuando se considera en relación con los casos de seguridad cibernética, la cuarentena de en línea se puede ver como una extensión de los marcos existentes para la protección antimalware.
Cuando se aplica al problema del discurso de odio, la cuarentena se sitúa entre los dos extremos éticos de permitir o prohibir por completo la publicación de ciertos mensajes. Permite a los destinatarios de esos mensajes (u otros moderadores) decidir si desean leer los mensajes o no, y, si deciden leerlos, si desean permitir que se publiquen o no.
Sin embargo, a pesar del atractivo de esta propuesta, los propios autores reconocen la dificultad de su empeño, pues su trabajo está basado en el análisis textual, en secuencias de palabras. Otros códigos, como las imágenes, músicas o voces que pueden constituir un meme, quedan fuera de este análisis. Por tanto, si bien su idea resulta atractiva, los investigadores concluyen que “claramente, queda mucho por hacer”.