Septina-4. Transcripción-1 de unión a octámero. Entender los términos de la genética parece imposible para el común de los mortales. Y, por lo visto, también para Excel.

Solo el año pasado, cerca de 700 publicaciones científicas con contenido sobre genética tenían errores en el nombre de los genes. De hecho, se estima que uno de cada cinco papers que mencionan genes contiene este tipo de fallos. El problema no está en que los investigadores no sepan lo que hacen o sean descuidados. Está en el popular programa de hojas de cálculo de Microsoft.
Un exceso de corrección
Puede parecer una simple molécula en forma de hélice, compuesta por cuatro tipos diferentes de nucleótidos. Pero el ácido desoxirribonucleico (ADN) es de todo menos sencillo. Sus estructuras guardan las instrucciones de la vida. El libro de montaje y funcionamiento de cada uno de los seres vivos que pueblan el planeta. De hecho, almacena tal densidad de información que se calcula que en un solo gramo de ADN podríamos guardar 215 millones de gigabytes de datos.
Así, el estudio de la genética es, cada vez más, el estudio de los datos. Los números y códigos de los miles de genes conocidos hasta el momento que se acumulan en las largas listas y bases de datos que después los investigadores utilizan para profundizar en lo desconocido. El problema es que, hasta ahora, un genetista tenía más bien poco de científico de datos. Y el uso de una herramienta de hoja de cálculo sencilla como Excel se ha convertido en un problema.
La primera señal de alarma apareció en 2004. Un paper publicado ese mismo año resumía un quebradero de cabeza que parecía fácil de resolver: la función de autocorrección de Excel estaba cambiando los nombres de algunos genes por palabras que nada tenían que ver con la genética. ¿Por ejemplo? Septina-4, abreviado como SEPT4, era cambiado por “4 de septiembre”. Y transcripción-1 de unión a octámero, abreviado como OCT1, por “1 de octubre”.
Un problema en aumento
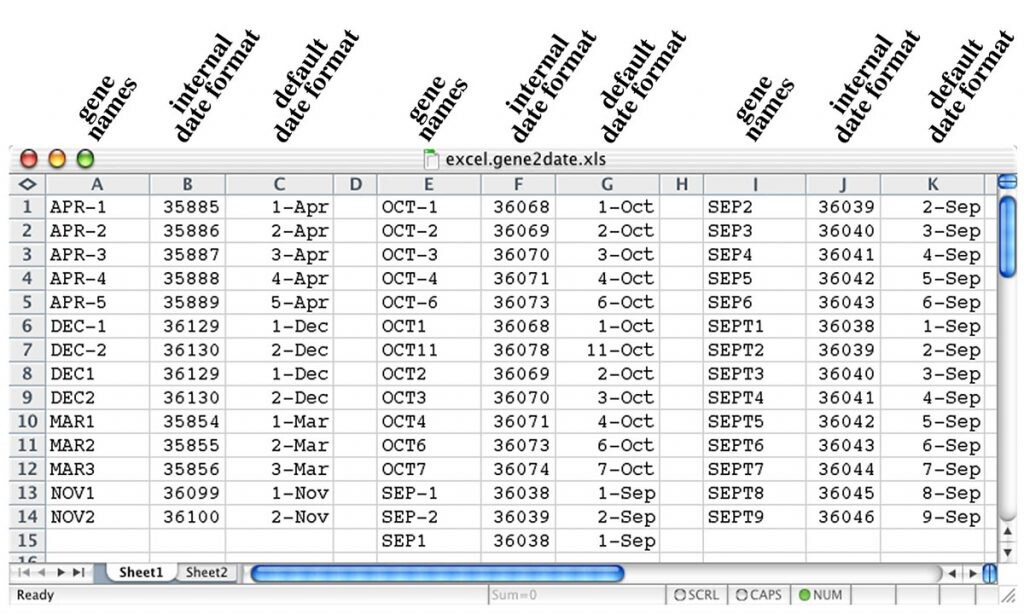
En ese primer artículo, se aconsejaba a la comunidad científica que prestase atención a este error, porque podía acabar echando por tierra una investigación. Sin embargo, 12 años más tarde, el problema no solo no había desaparecido, sino que empezaba a ser preocupante. Otro paper publicado en 2016 señalaba que uno de cada cinco artículos en las revistas de genética más importantes contenía errores generados por la función de autocorrección de Excel.
La comunidad investigadora se dispuso a atajar el problema de raíz. No parecía que el grueso de los genetistas fuese a dejar de usar Excel. Así que la solución pasaba por cambiar las abreviaturas de los genes. En 2017, el HUGO Gene Nomenclature Committee, que estandariza los nombres de los genes humanos, anunció que empezaría a modificar estas abreviaturas. Desde entonces, 27 han sido cambiadas. Ahora, por ejemplo, SEPT4 se llama SEPTIN4.
La situación, sin embargo, no ha mejorado en estos últimos cinco años. Un nuevo estudio liderado desde la universidad australiana de Deakin, publicado en el mes de julio, señaló que casi uno de cada tres artículos con listas de genes creadas en Excel y publicados entre 2014 y 2020 contenía errores en el nombre de los genes. Mientras en 2017 se habían registrado 440 papers con errores, en 2020 se contabilizaron 698.
El ADN no cabe en Excel

Aunque el error es conocido desde hace casi 20 años, se sigue reproduciendo. Ni siquiera el cambio de nomenclaturas parece haber ayudado mucho, dado que las bases de datos de genes están, en ocasiones, sin actualizar. Tal como señala el autor principal de los dos últimos papers publicados (2016 y 2021), Mark Ziemann, el problema no está tanto en que se puedan alterar los resultados finales de una investigación, algo que no suele suceder. La cuestión está en que estos errores pasen el filtro de la revisión por pares y acaben siendo publicados en revistas científicas, minando la reputación de estas y de las instituciones responsables de la investigación.
Para Ziemann, existen dos alternativas. Una pasa por estar más atentos. La otra, por olvidarse de Excel. De acuerdo con el investigador, podría bastar con prestar más atención a los datos e incorporar una serie de medidas. Por ejemplo, dar formato a las celdas de la hoja de cálculo antes de copiar los datos o hacer una revisión final (al ordenar la columna de los nombres, los errores saldrán a la luz todos agrupados). Si no, la otra opción es pasar de Excel.
“En genética y otras ciencias que manejan gran cantidad de datos, los lenguajes informáticos como Python y R son muy superiores a las hojas de cálculo. Ofrecen ventajas que incluyen técnicas analíticas mejoradas, reproducibilidad y auditabilidad”, señala Ziemann. “Puede que sean más difíciles de aprender al principio, pero los beneficios valen la pena a largo plazo. Excel es adecuado para la entrada de datos a pequeña escala y el análisis ligero […] Cualquier conjunto de datos de más de 100 filas no es adecuado para una hoja de cálculo”.
La genética, como ha pasado con otras ciencias y con tantos otros sectores de la sociedad, ya no puede separarse de la informática. La ciencia de datos (y las matemáticas) continúa conquistando espacios. Para el resto de mortales, los que no entendemos qué significa transcripción-1 de unión a octámero, Excel seguirá siendo suficiente.
En Nobbot | Cómo crear gráficos en Excel para hacer más comprensibles los datos
Imágenes | Unsplash/National Cancer Institute, National Cancer Institute 2, Nature Blogs