
Empresario y filósofo, Ricardo Alonso Maturana es el promotor y director de Gnoss, una empresa que pretende integrar inteligencia humana y tecnológica en un nuevo programa de inteligencia artificial. Entre sus clientes figura el bicentenario Museo del Prado.

Desde Logroño, donde tienen la sede, han creado una plataforma de desarrollo para construir y explotar grafos de conocimiento –nodos de millones de datos entrelazados-. Y también servicios asociados de procesamiento y comprensión del lenguaje natural que sirven de apoyo a decenas de empresas.
Baste el ejemplo de cómo han desarrollado el motor tecnológico que hay detrás de la web del Prado, un proyecto del Área de Desarrollo Digital del Museo, para entender el potencial de futuro que tienen los grafos de conocimiento, que en su presentación para las personas adoptan la forma de web semántica o web de datos enlazados.
«los grafos de conocimiento son la ‘mente’ de nuestros sistemas
– Tim Berners-Lee, el padre de internet, ya acuñó el término web semántica en 2001. Gnoss es el mayor promotor de este tipo de red en España. ¿Cómo ha cambiado el concepto en estos años?
Tim Berners-Lee la definió como una extensión de la web que proporcionaba una solución a limitaciones relativas al formato, integración y recuperación de la información. Las tecnologías semánticas son en la actualidad un componente clave del programa de inteligencia artificial. Hoy en día, la web semántica, que es la que ofrece Google, es una reformulación de la “www” en forma de grafo de conocimiento, que es la condición para desarrollar explotaciones inteligentes de la misma. La idea esencial es que las tecnologías semánticas y de representación del conocimiento son ya, pero lo serán aún más, el intérprete de la inteligencia artificial.
– ¿Algo así como el nexo necesario entre el hombre y la máquina?
Para nosotros es evidente que una persona es Juan o Luisa. A partir de ahí atribuimos a cada cual lo que le corresponda. Por ejemplo, que Juan trabaja en el Ministerio de Educación o que Luisa es más alta que Juan. La condición para construir inteligencia artificial es que nuestros sistemas sean capaces de reconocer esas mismas entidades y relacionarlas. Con la clase de cálculo adecuada, en este caso la llamada lógica de predicados de primer orden, los ordenadores son capaces de enlazar cualquier entidad con una enorme cantidad de entidades y de descubrir relaciones que para nosotros hubieran sido imposibles de descubrir. Un grafo de conocimiento se puede definir como ese artefacto que condensa entidades y relaciones. Metafóricamente hablando, podríamos considerarlo como la ‘mente’ de nuestros sistemas.
«queremos que cada cual construya su propio prado»
– ¿Cómo ha aplicado estos avances en la nueva web del Museo del Prado?
En el proyecto del Prado construimos un grafo de conocimiento capaz de enlazar el conjunto de informaciones que produce el museo: autores, obras, entradas de la enciclopedia, exposiciones… El objetivo era hacer que la web del museo funcionara como un espacio de conversación y no de simple publicación. Queríamos que cada cual pudiera construir su propio Prado, ya sea este el de las ninfas, las rosas antiguas, los instrumentos musicales, la caza o el retrato real ecuestre. El Prado puede responder a quien pregunte por “cuadros de la escuela española del siglo XVII que contienen dragones”, y a cualquier otra por el estilo que quepa imaginar.
– ¿Se puede entender como una web que se retroalimenta?
El proyecto ha integrado en un grafo interrogable al conjunto de los activos de conocimiento de la institución. Ahora, cualquier contenido que genera el Prado se incorpora al grafo, ampliándolo y enriqueciéndolo. Cuando el proyecto fue lanzado en diciembre de 2015, se pusieron a disposición del público 10.000 obras. Hoy pueden visitarse más de 16.000. El objetivo es que estén en la web las más de 27.000 que componen la colección, enlazadas entre sí, pero en el futuro también con información proveniente de terceras fuentes.
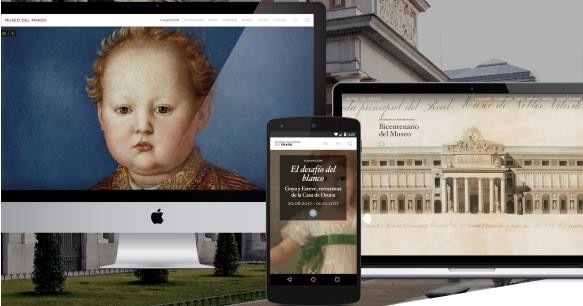
“Un nuevo modelo de museografía digital”
– ¿Vamos hacia una nueva manera de entender los museos?
En el Prado, ahora podemos buscar por autores, temas, técnicas, épocas, elementos que forman parte de las obras… y también por cualquier combinación de cualquiera de esas cosas a la vez. La idea era hacer accesible todo el contenido del museo a todo el mundo de un modo sencillo y adecuado a los intereses del usuario. Creemos que el proyecto ha supuesto un nuevo modelo de museografía digital, consiguiendo trasladar y extender a la web el conocimiento acumulado por el museo en sus 200 años de vida. Aparte de la gran aceptación del público, la web del Prado obtuvo dos premios Webby, algo así como los Óscar de internet, en 2016. Un gran logro que a nosotros, como parte del proyecto, nos llena de satisfacción.
– ¿Qué otros museos en el mundo están en la vanguardia en lo que a innovación tecnológica se refiere?
Hay algunos museos que están representando semánticamente sus datos, pero no los están utilizando, como el Prado, para construir la experiencia del museo en la red. Esto marca una gran diferencia. El British Museum o el Smithsonian están trabajando en la representación semántica de sus contenidos. Para nosotros, el proyecto del Rijks Museum supuso una enorme inspiración y también el trabajo de instituciones como la Getty Foundation.
“El Prado digital es pura actualidad”
– ¿Sale muy cara la transición tecnológica-digital en el campo de la cultura?
La cultura busca, por defecto, trascender, especialmente en el tiempo. Así que los proyectos tecnológicos a largo plazo deberían ser algo inherente a la divulgación cultural. Cuando presentamos el proyecto del Prado, dijimos que su ejecución tenía que ver con la actualidad del museo, si entendemos como actual lo que permanece. Todas las instituciones de la memoria luchan por permanecer y, en este sentido, El Prado en la Web, ese Prado digital ubicuo y abierto las 24 horas, representa uno de los modos de la actualidad del Prado. Visto así, el coste es relativo, tirando a bajo, ya que utilizando la tecnología de un modo adecuado los beneficios a medio y largo plazo para todos superan siempre con creces cualquier tipo de inversión.
“No creo que el rencoroso HAL llegue a existir”

– ¿Qué peligros puede acarrear dotar de tanta capacidad a la inteligencia artificial?
Puede que sintamos que estamos abriendo la caja de Pandora, pero lo fundamental es que seamos capaces de pensar bien colectivamente y de utilizar la inteligencia artificial de un modo adecuado. No olvidemos que son las personas las que dotan de intención al uso de la tecnología. No existe HAL, el rencoroso ordenador de ‘2001, una odisea en el espacio’, ni probablemente vaya a existir con ese grado de autonomía e intencionalidad. Pero si disponemos de información de calidad y de las intenciones adecuadas, podremos tomar mejores decisiones y, en consecuencia, podremos dedicarnos a lo realmente relevante para las personas, que son las relaciones con otras personas, de un modo más útil y efectivo.
“Hay una fiebre del dato como hubo la fiebre del oro”
– ¿Se acerca la web semántica a ciertos postulados ya intuidos por Borges?
Borges tiene un cuento que lo expresa muy bien: ‘Del rigor en la Ciencia’. Cuenta la historia de la evolución de la cartografía en un cierto imperio, donde el empeño de los cartógrafos era hacer mapas cada vez más minuciosos y precisos. Con el tiempo, los mapas ocupaban cada vez más espacio hasta el punto de que, finalmente, los cartógrafos “levantaron un Mapa del Imperio que tenía el tamaño del Imperio”. Es un cuento tan corto, 10 líneas, que da miedo. Pero es una excelente metáfora del apetito desmesurado por acumular e interpretar datos. Podríamos decir que hay una fiebre del dato, como la hubo del oro en otras épocas.
– ¿Tantos datos acumulados no terminarán conformando la borgiana Biblioteca de Babel?
Me inclino más por ‘Funes el memorioso’. Funes dispone de una memoria tan precisa que recordar una hora le lleva una hora. La historia es la misma y supongo que nos dice algo sobre el hecho esencial de que ninguna representación, por muy minuciosa y precisa que sea, puede suplantar a la realidad. Nuestro programa de inteligencia artificial tiene una especie de límite gödeliano, un límite que podemos intuir, pero no demostrar: y es que la espontaneidad y vastedad de la realidad no podrá ser reducida a datos, por mucha capacidad de la que dispongamos. El ‘factor humano’ seguirá siendo la clave a pesar de todo.
“Se están dando movimientos profundos en la tecnología”
– Pero ese ‘factor humano’ no puede ya con la ingente cantidad de datos que se manejan. ¿La idea es que gracias a los datos entrelazados, el expurgo inteligente de la información lo realicen las máquinas?
Esa es la idea. Primero hay que entender cómo hemos ido generando información y datos, en cantidades que se incrementan exponencialmente. La mayor parte de esa información está distribuida en sistemas heterogéneos, pero contienen las mismas entidades, se refieren a las mismas personas, lugares, organizaciones, etc. Es importante darse cuenta de que existe algo así como una tectónica de la tecnología, un conjunto de movimientos muy profundos que, por decirlo de algún modo, van hacia alguna parte.
– ¿Y hacia dónde tienden estos movimientos profundos?
Ahora mismo, a integrar información distribuida y heterogénea y hacerla fácilmente interrogable. Vamos hacia un nuevo ecosistema digital donde los datos entrelazados son capaces de responder a preguntas cada vez más complejas y sofisticadas. Se trata de un esfuerzo enorme, tanto en términos de representación del conocimiento como de cálculo. A ese movimiento tectónico de la tecnología es a lo que nos referimos ahora cuando hablamos de inteligencia artificial.
“Los datos, además de masivos, han de ser inteligentes”
– ¿Puede la web semántica transformar la inteligencia artificial en inteligencia cognitiva?
La cognición humana es mucho más que representación, patrones y cálculo. Sin embargo, es cierto que el corazón de cualquier proyecto inteligente ha de disponer de un núcleo semántico que permita una comunicación e interacción sencilla, ‘humana’, entre las máquinas y las personas.
– Es decir, ¿una inteligencia no tan artificial?
Hemos descrito Gnoss como una plataforma cognitiva porque emula una serie de funciones cognitivas, como la memoria, el lenguaje o el razonamiento, que son las que están haciendo posible el renovado programa de inteligencia artificial. A eso es a lo que nos dedicamos en Gnoss. Se habla mucho de que los datos son la gasolina de la nueva economía, por eso consideramos que es tan importante hacerlos inteligentes. A la idea de datos masivos –big data-, nosotros añadimos la condición de que sean ‘inteligentes’, de que cada dato sepa qué es y representa, de que incorpore una interpretación básica de sí mismo: smart data.
En Nobbot | Así se reivindican los museos en una red tan artística como Instagram
Imágenes | Gnoss